Direction of maximum variance
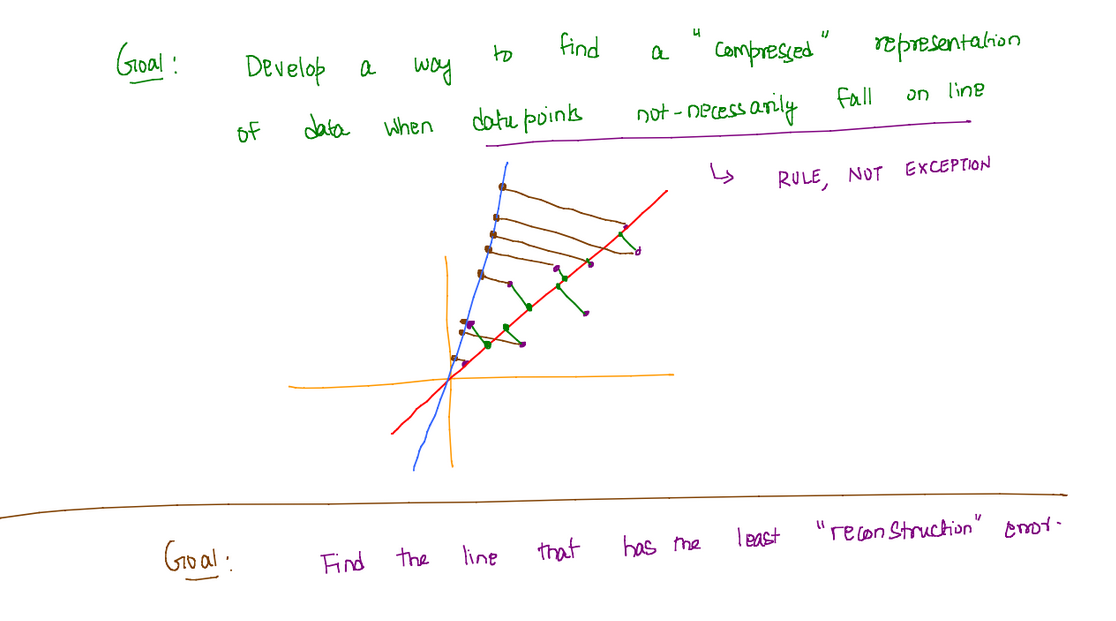
Let’s say we have a set of datapoints for which we wish to obtain a “compressed” representation using a line. The line that can best act as a representative for these data points must have the minimum reconstruction error.
For any datapoint and the representative line , the representation of on is the projection of on , i.e. .
To find such a , we wish to obtain where,
In this above error term, the term is independent of . Thus the error can be re-written as,
And thus the optimization problem can becomes a maximization of error instead.
Where is the covariance matrix for the random vector . If we recall the properties of the covariance matrix, we can see that the above form of the error function heavily resembles the variance of a random vector.
Also notice how the formula we arrive at is similar to the covariance formula for a random vector, with just the mean being 0. This means that centering the data is essential for variance maximization.
Thus the best representative line will be the one that captures that maximum variance in the dataset.
Residual Analysis
The residue left after determining a representation for need not be error. It can still hold some information crucial for a full reconstruction of the original dataset.
Some observation about the residues -
- All residues are orthogonal to the first representation .
- Any line which minimizes the sum of errors w.r.t the residuals must also be orthogonal to as all such lines would lie in the orthogonal complement of .
If are our original datapoints, the residues left after representing them using would be
We can then find another line in the orthogonal complement of which would minimize the sum of errors w.r.t these residuals and yield us new residues
Thus the residue after rounds would be,
because after rounds, we’d be left with orthonormal basis which would span all of .
Note - If the datapoints lie in a low dimensional subspace of then the residues would become 0 much earlier than rounds.
For any , such that
We want this representation term to be as large as possible for a better fit.
Eigenvalues of the Covariance Matrix
The optimization problem discussed above can be solved using the Hilbert’s Min-Max Theorem. This tells us that is the eigenvector of corresponding to the largest eigenvalue of .
If is an eigenvector of , we can say that
This is exactly the optimization error term we used earlier to restructure the error as variance. Thus we can say that the largest eigenvalue of the covariance matrix is literally the variance of the data projected onto .
Because the covariance matrix is symmetric, the eigenvectors for it will be orthogonal. Thus the eigenvector corresponding to the second highest eigenvalue will naturally lie in the orthogonal complement of and would correspond to the variance of the data projected onto .
Sequentially, all eigenvalues of the covariance matrix would in-turn correspond to the variance of the data projected onto the eigenvector corresponding to them.
Rule of thumb for dimensions
The most common assumption is that any data point is made up of two components. The actual signal and the random noise . Because this noise is random in nature, it doesn’t have a particular pattern which it follows. It has not preferred direction, tends to be small in magnitude, and contributes a small and roughly equal amount of variance in every direction.
Thus by looking at the eigenvalues of our covariance matrix, we can say that the smaller eigenvalues may correspond to this random noise and the eigenvectors corresponding to these eigenvalues are redundant for a proper reconstruction of the original data. So instead of trying to capture all the variance in our original data, we can only use some top eigenvalues and their corresponding eigenvectors to capture some threshold of variance, typically 0.95.
We can identify our top directions by doing
Because all eigenvalues correspond to variance which is non-negative, this summation will be non-decreasing.
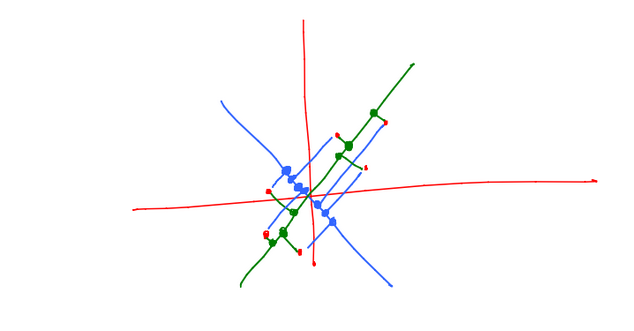
Let the green line represent and the blue line represent . Notice how the variance of the data along is much more than the variance of the data on .