Table of Contents
Locality of Reference
Locality of reference is a phenomenon when programs tend to access the same memory location or nearby memory locations within short intervals of time.
Types -
- Temporal Locality - Recently accessed memory locations are likely to be accessed again.
- Spatial Locality - Memory locations close to the recently accessed memory are likely to be accessed.
- Sequential Locality - Access in strictly increasing order of address.
This phenomenon allows for caching a block of memory to be efficient. Currently demanded localities are kept in a smaller and faster memory called cache.
Working of Cache Memory
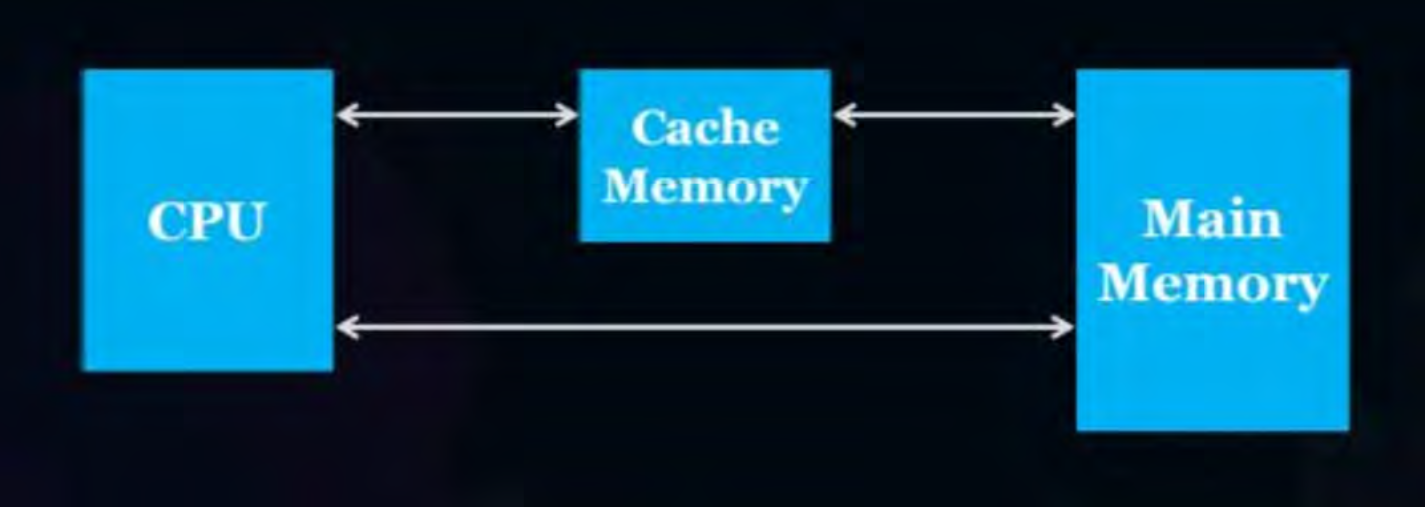
Caching is temporarily storing copies of certain content of the main memory for a ease of access.
The memory used for caching is called a cache memory. Cache memory has a faster access time than main memory but is typically smaller in size. On-chip Cache memories are in the CPU itself.
When the CPU accesses -
- On-chip Cache memory it doesn’t require system buses. The cache can be accessed similar to registers.
- Main memory it needs system buses.
Keywords -
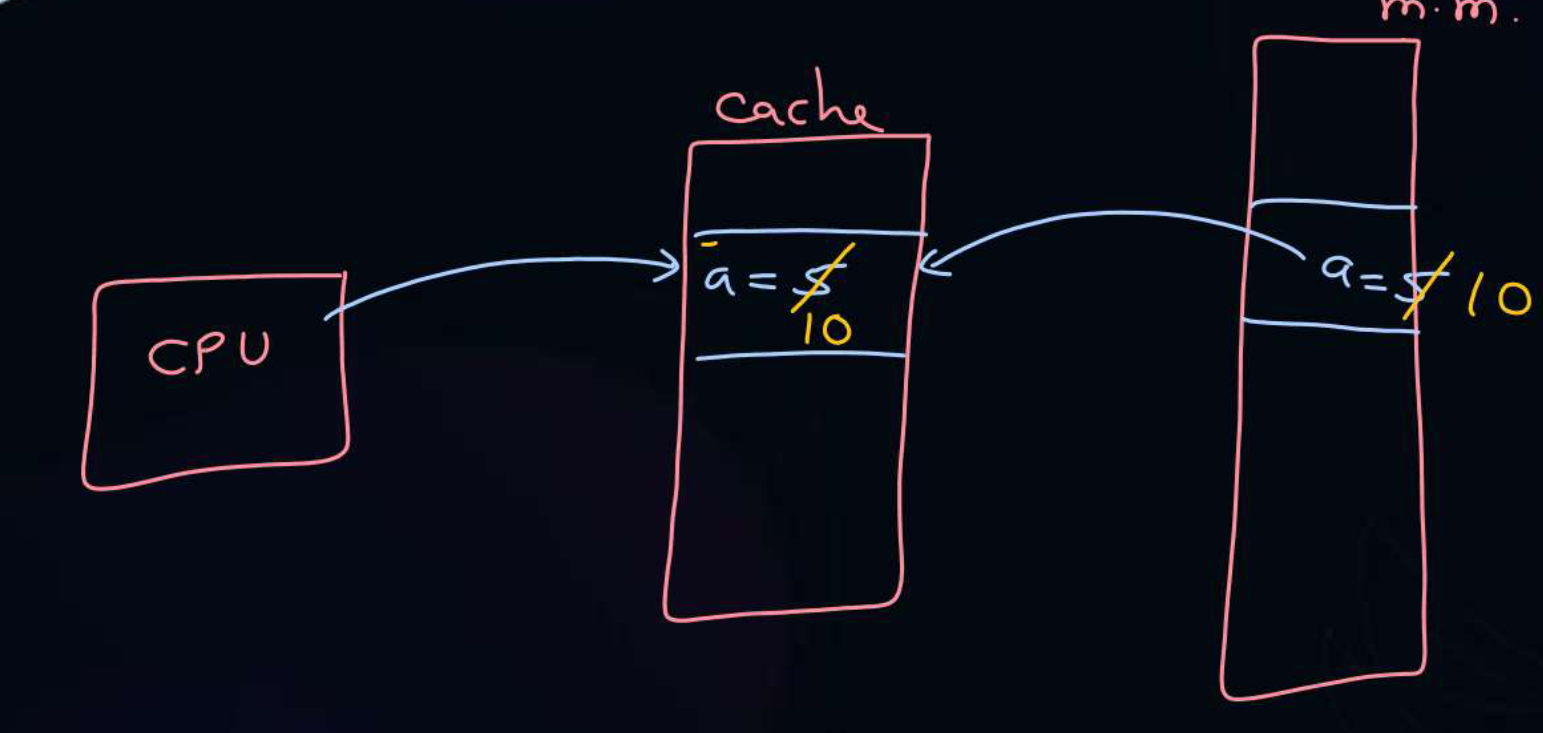
- Cache Hit - When demanded CPU content is present in Cache.
- Cache Miss - When demanded CPU content is absent in Cache.
- Hit Ratio - Fraction of times a Cache Hit occurs in all memory references.
Block
More specifically, a block is a fixed-size contiguous group of memory words transferred between the main memory and cache memory as a single unit.
Example - Whenever a Cache Miss occurs, the CPU retrieves the content from the Main Memory itself. But because locality of reference is known, a neighbourhood around that content is brought to the cache to make future memory accesses more efficient. This neighbour is a block.
Average Memory Access Time
Both a Cache Miss and a Cache Hit take some time for performing the content transfer. So the average memory access time is -
Types of Cache Access
Simultaneous Access
The memory read operation is performed on both the cache memory as well as the main memory. Hence this is also called a parallel access.

The average memory access time is -
Here is the cache memory access time and is the main memory access time.
Hierarchical Access
The memory read operation is performed to the main memory only when a Cache Miss occurs. Hence this is also called as serial access.
The average memory access time is -
The additional in the second term of the formula is called the “cache search/lookup time” because in the case of a cache miss the cache access is not for retrieving content from cache but to check for its existence.
Cache search time is zero in the case for parallel access.
In such a memory organization -
- The Cache Memory is also called as the Top Level memory.
- The Main Memory is also called as the Bottom Level memory.
When to use which formula for Avg. Memory Access time?
If a question has the words "cache memory access time" and "main memory access time" mentioned, only then move onto using the formulas for Simultaneous or Hierarchical access. - If "Hierarchy" or "Level" is mentioned, we are dealing with Hierarchical Access. - Else we are dealing with Simultaneous Access.Otherwise, if the question just mentions “time for cache hit” and “time for cache miss”, use the generic formula.
See Question 1 for a simple example.
Memory Access Time when Locality of Reference is used (Cache Miss Penalty)
In the previous cases we were just looking at the cases where on a Cache miss we retrieve the data directly from the main memory. But on a cache miss, the block in which the data belongs to needs to be brought in the cache memory for future usage as well.
Let the block transfer time be . This is also called as Cache Miss Penalty.
Then,
- Simultaneous Access -
- Simultaneous Access -
Cache Write or Write Propagation
Write propagation means that, if the CPU performs a write operation on some data in the cache memory, then that same data should also be updated in the main memory.
Write Through
If the CPU performs a write operation in the cache, it performs a write operation in the main memory simultaneously/parallelly. The data in the cache and the main memory is updated together.
- Pro - No inconsistency between the content in the cache memory and content in the main memory.
- Con - Time consuming because write operation is performed on the main memory irrespective of hit or miss in the cache.
Because the cache and main memory are accessed simultaneously, the cache memory would use simultaneous access. Thus, the time required for one read and one write operation is -
Out of all cases of read/write operations hitting/missing, the cache memory is sufficient by itself only when a read-hit occurs. For rest of the cases the main memory is involved too. This causes a lower effective hit ratio for Write Through cache when compared with Write Back cache.
Write Back
If the CPU performs a write operation in the cache, the same content in the main memory is not updated simultaneously. Instead the content in the main memory is updated when a block is replaced in the cache memory.
- Pro - Time saving compared to Write-Through.
- Con - Inconsistency between the content in cache memory and main memory.
Dirty Block
Any block that has been written over is called a dirty/modified block. For any block in the cache memory -
- If no write was performed on that block - Directly replace the block without any write in main memory.
- If write was performed on the block (If it’s a dirty block) - Perform write back for the block.
Unlike Write Through cache, there’s no requirement of Write Back caches requiring strictly Simultaneous or strictly Hierarchical access. The average memory access time is -
- Simultaneous Access -
- Hierarchical Access -
write back time is -
Write Miss
Write miss are handled in two ways, by using Write Allocate or by using No Write Allocate.
Write Allocate
On a write miss the block is loaded into the cache and then written in the cache itself. Usually used with Write Back cache.
Write Back cache with Write Allocate -
- Read -
- Hit - CPU reads content from cache.
- Miss - CPU reads content from main memory and brings the missing block to the cache memory by replacing an existing block if needed. If a dirty block is replaced, write-back to the main memory.
- Write -
- Hit - Perform write in cache.
- Miss - Bring the missing block to the cache memory by replacing an existing block if needed and then perform the write operation on it in the cache. If a dirty block is replaced, write-back to the main memory.
No Write Allocate
On a write miss the block is written in the main memory and not loaded into the cache. Used with Write Through cache.
Write Through cache with No Write Allocate -
- Read -
- Hit - CPU reads content from cache.
- Miss - CPU reads content from main memory and brings the missing block to the cache memory by replacing an existing block if needed.
- Write -
- Hit - Perform write in cache and main memory simultaneously.
- Miss - Perform write in main memory but do not bring missing block to the cache.
Cache Mapping
A cache line is the smallest data unit that is transferred between the cache and the main memory. In simpler words, a block in the cache memory is called a cache line.
Cache mapping is the rule/mechanism that dictates which cache line would hold which main memory block.
Direct Mapping
In direct mapping, each main-memory block is mapped to exactly one fixed cache line/index.
One index in direct mapping is one cache block. The below formula is applicable for Set Associative Mapping and Fully Associative Mapping as well, it’s just that the number of indices for those mappings are different.
Suppose if the cache memory has 10 blocks and the second block is holding the main memory block 52. If we lookup block 92 in the cache, it will be checked in the second block of the cache memory. Because the second block is already holding block 52, looking up block 92 in cache should be a cache miss. But how can we differentiate between the content in the cache block and the block being requested?
Tag
A tag is a part of the memory address and helps in identifying whether the requested block is present in its respective cache line or not.
Index
The cache block no. is also known as index in direct mapping.
Memory address layout
The tag and cache memory block no. make up the main memory block no.
But a memory address is byte/word addressable not block addressable. A block will be made up of some bytes/words, thus the memory address will be of layout -
- No. of bits for byte no./byte offset -
- No. of bits for main memory block no. -
- No. of bits for cache memory block no./index -
- No. of tag bits -
See Question 3 for an example.
Suppose the cache memory size and main memory size , but the byte offset is unknown. Assume byte offset to be . The index bits would be . The tag bits would be -
So we can say,
Cache Controller
The cache controller is a device which acts as the control logic for all cache related operations. The cache controller maintains a tag directory/metadata which holds all the tag bits and status bits.
Unlike the tag bits, the valid/invalid bit and dirty bit are not stored in the main memory address. Instead they are kept separately in the tag directory.
The tag directory size doesn’t depend upon the type of cache mapping used.
Tag bits
The bits required to denote a block tag.
Valid/Invalid Bit
Whenever we start our computer, the cache is initialized with garbage values. It is possible that when we lookup a memory address in the cache, the tag of this memory address matches the garbage value in the tag bit and invalid content is sent to the CPU. To avoid this we use valid/invalid bits.
- 0 means invalid
- 1 means valid
How it works -
- When the cache is initialized, all valid/invalid bits for each cache line are initialized with 0 signifying that all tag bits are garbage values.
- When a cache line is filled with a block from the main memory, this bit is set to 1 to signify that going forward the cache line would contain valid content.
Dirty bit
In write back cache when a dirty/modified block is replaced from the cache, the content in the block needs to be written to the main memory. To keep track of modifications in a cache block, we use dirty bits.
- 0 means the cache block has not been modified.
- 1 means the cache block has been modified and upon replacement should be written to the main memory.
Set Associative Mapping
In set associative mapping, each index corresponds to a set containing multiple cache lines, and a memory block can be placed in any line within its indexed set.
From here, using the no. of indices we can calculate the number of bits required for indices consequently calculate the tag bits and tag directory size. The memory address layout now looks like -
No matter which type of mapping or associativity we use, each block in the cache memory would still require a tag. Thus the formula for the tag directory size stays the same as the one mentioned under Direct Mapping.
However, the tag bits required for an associative mapping will increase which will consequently increase the size of the tag directory.
By each time increasing the associativity by a factor of 2, we increase the tag bits by 1 and decrease the index bits by 1. Thus if the set associativity is , the index bits are decreased by . In direct mapping memory address size = Tag Bits + Cache line bits, but in -way set associative mapping,
How it’s implemented
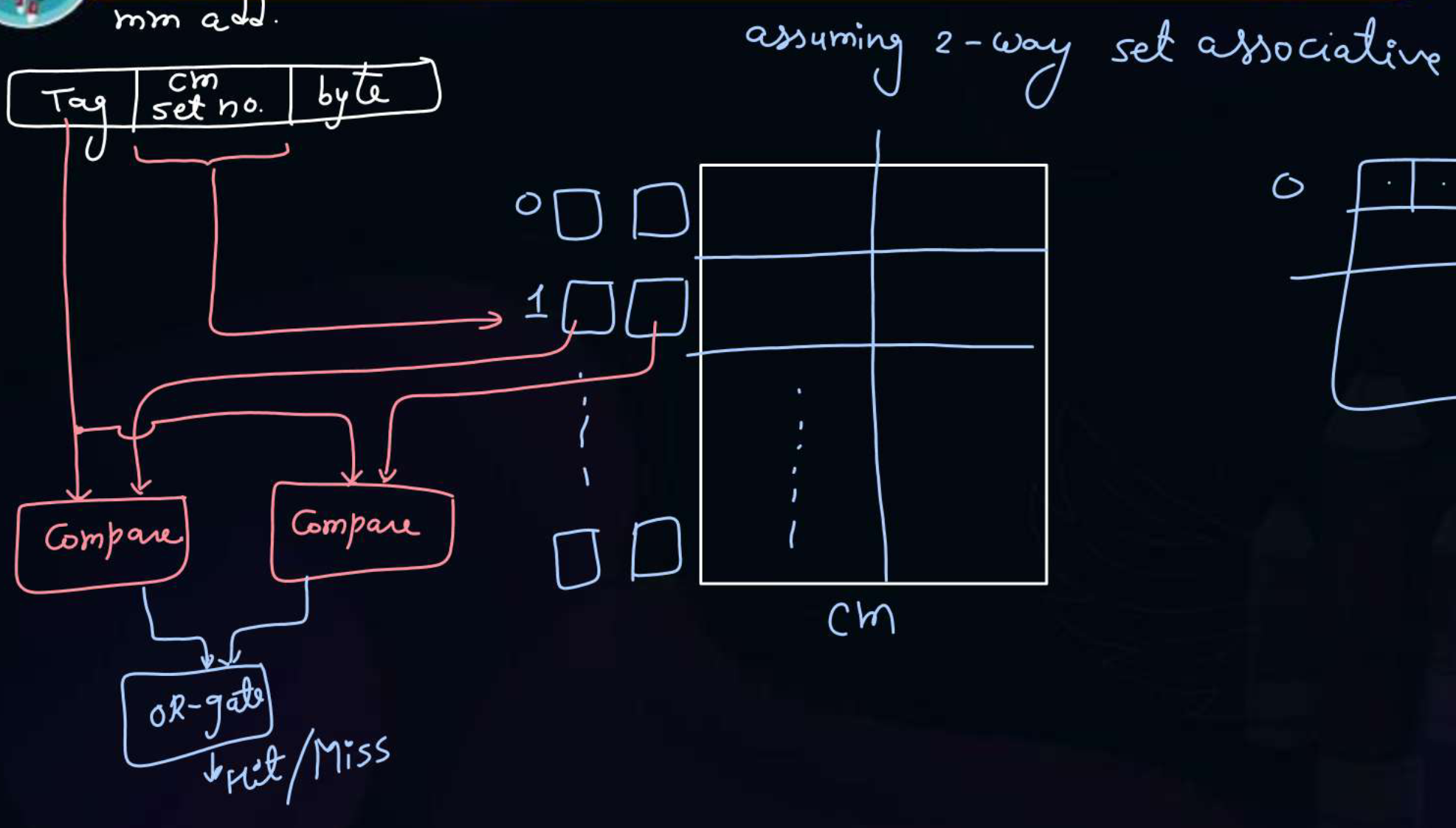
Assume that we are dealing with a 2-way set associative cache. In such a cache, for each set there would exist two tags for each block in a set. These tags are parallelly compared with the tag of the memory address being requested. If any of the tag matches, we have a cache hit else a cache miss.
The higher the associativity, more such tags need to be compared in parallel and thus increasing the complexity and expense.
Fully Associative Mapping
In fully associative mapping, any main-memory block can be placed in any cache line. There’s no fixed mapping between memory blocks and cache lines.
In a fully associative cache, the index has zero bits. The memory address layout looks like -
The formula for the tag directory size stays the same as the one mentioned under Direct Mapping. Here the tag bits = m.m. block no. so the same formula can be re-written as,
Block Replacement Policy
In set associative mapping and fully associative mapping where each index holds multiple blocks, which block to replacement when a cache miss occurs?
Replacement Policies -
- FIFO
- Optimal
- LRU (Least Recently Used) - Replace the block which hasn’t been used for the longest length of time.
Types of Cache Miss
A cache miss can only be one of three types -
- Cold or Compulsory Miss - when a block is accessed for the first time, before it has ever been loaded into the cache.
- Capacity Miss - When a block is evicted because the cache is too small to hold the working set, and that block is later requested again.
- Conflict Miss - When the cache is not full but a block is still evicted due to conflict in the set and then requested again later. Only occurs in direct mapping and set associative cache.
If a miss is not a cold miss, only then check if it’s a capacity miss. If a miss is not a capacity miss either, only then it’s a conflict miss.
To decrease cache misses -
- Cold Miss - Increase the block size.
- Capacity Miss - Increase cache size.
- Conflict Miss - Increase associativity.
Hardware Implementation of Cache
🥱🥱🥱🥱🥱🥱🥱🥱🥱🥱🥱🥱😴😴😴😴😴😴😴😴😴😴
Multi-level cache
Goals of using cache memory -
- Minimize Access Time - Use smaller sized cache
- Maximize Hit Rate - Use larger sized cache
- Minimize Miss Penalty
To achieve this, we use a multi-level cache to achieve both the contradictory goals.
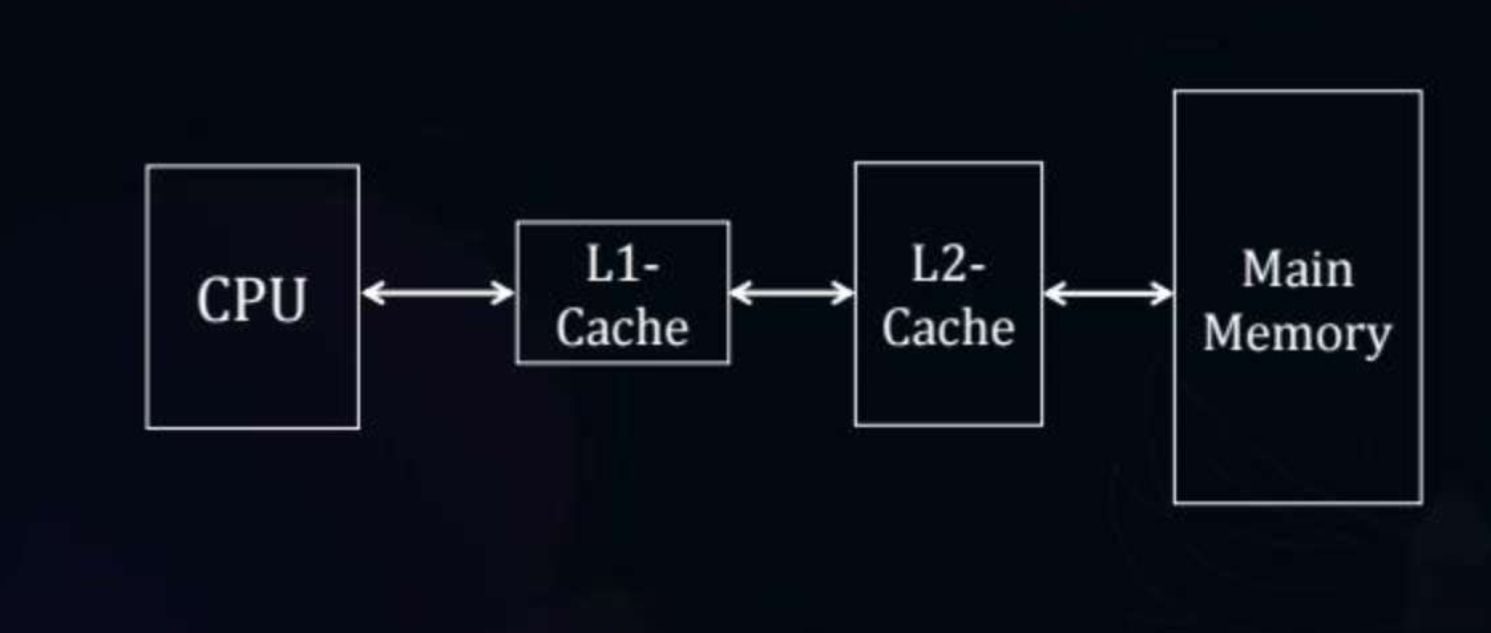
How it works -
- Check if the request content exists in L1 cache.
- If it doesn’t then check if it exists in L2 cache.
- If it doesn’t then access main memory.
Simultaneous Access
Average memory access time would be -
Hierarchical Access
Average memory access time would be -
Probability of Access
Say in a multi-level cache -
- 80% of the requests require only L1 cache.
- 18% of the requests require only L2 cache.
- 2% of the requests require only the main memory.
We can say that -
Using this information too, we can find the hit ratio for each level of cache and the main memory.
Dual Cache
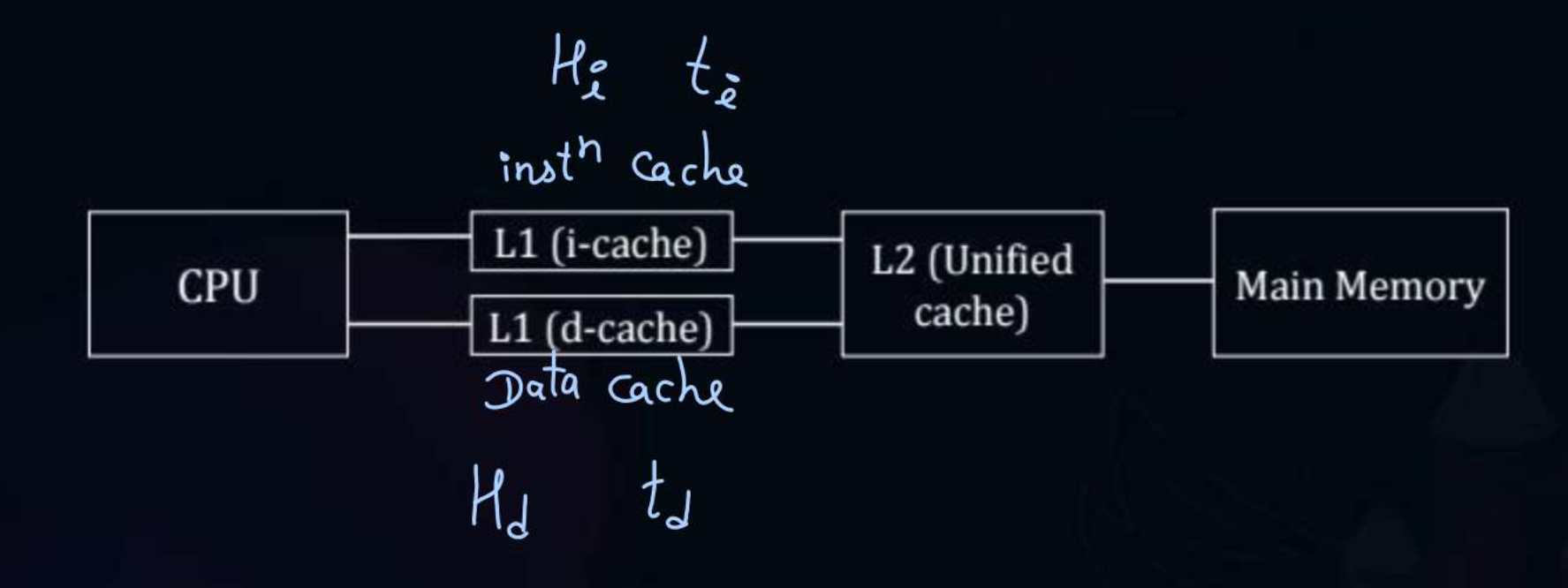
The level 1 cache is split into two caches, one specifically for instructions and the other specifically for data. Both caches can be accessed simultaneously in parallel by the CPU.
Here if the cache uses simultaneous access,
The above formula can be adjust for hierarchical access similarly to previous usages.
Cache Inclusion Policy
Blocks in L1 cache should also be present in L2 cache.
Cases -
- L1 hit - CPU reads content from L1.
- L1 miss but L2 hit - CPU reads content from L2. A block is copied from L2 to L1, if a block in L1 is evicted it is written back to the main memory if needed. There is no role of L2 in case of block eviction.
- L1 miss and L2 miss - CPU reads content from main memory. A block is copied from main memory to L2, then from L2 to L1. Any evicted block from L1 or L2 is written back to the main memory if needed.
Cache Exclusion Policy
Blocks in L1 cache should not be present in L2 cache.
Cases -
- L1 hit - CPU reads content from L1.
- L1 miss but L2 hit - CPU reads content from L2. A block is moved from L2 to L1 and removed from L2. If a block in L1 is evicted it is moved to L2.
- L1 miss and L2 miss - CPU reads content from main memory. A block is copied from main memory to L1 directly without moving it to L2. Any evicted block from L1 is moved to L2.
Here L2 holds blocks evicted from L1. Thus it is also called as victim cache.
Questions
Q1) If in a two level memory hierarchy, the top level memory access time is 8ns and the bottom level memory access time is 60ns, the hit-rate required is __ for the average access time to be 10ns. What is __?
Here as “memory hierarchy” and “two level” is mentioned, we are dealing with a hierarchical access cache organization. So,
Q2) What is the size of data sent from the CPU to main memory when:
1. For write hit, a write through cache is used 2. For write miss, a write through cache is used 3. For write hit, a write back cache is used 4. For write miss, a write back cache is usedFor any write operation, the CPU sends 1 data item of 1 byte or 1 word to the cache/main memory depending upon what type of cache is used.
- Write hit in Write Through - 1 data item, because in Write Through cache both cache and main memory is written simultaneously regardless of hit or miss.
- Write miss in Write Through - 1 data item, same reasoning as above.
- Write hit in Write Back - No data item, because the write operation is performed in the cache memory and not the main memory.
- Write miss in Write Back -
- If using write allocate - No data item, because the missing block is brought from the main memory to the cache memory and then the write operation is performed on the cache memory.
- If using no-write allocate - 1 data item, because the write operation is performed directly on the main memory without bring the block to cache.
Q3) If the main memory is of size 1MB with a block size of 16 bytes, and the cache memory is of size 64KB, how many bits are required for the Tag, cache block no., and byte no.?
- Here the memory is of bytes. Thus the memory address is made up of 20 bits.
- A block is of 16 bytes, thus 4 bits is required for byte no.
- The number of blocks in the main memory is . Thus 16 bits are required for the main memory block no.
- The main memory block no. is made up of Tag and cache memory block no. The number of blocks in cache memory is . Thus 12 bits is required for cache memory block number.
- The remaining 4 bits of the main memory block no. are for the block tag.
Thus the layout is -
Q4) In a program execution 36% of the instructions require load and store. CPI without memory stalls is 2. The program experiences 2% miss for instruction cache and 4% miss for data cache. The cache miss penalty is 200 cycles. Answer the following -
1. CPI with memory stalls 2. Performance gain if perfect cache is used.Here of the instructions would need to be fetched from the cache. Only of these would be a miss and require 200 cycles.
of the instructions would require data fetching from the cache and of these would be a miss.
Each instruction execution would require 2 cycles at least. On top of those 2 cycles, cycles for instruction and data fetch would also be required. Thus the average cycles required per instruction are -
In an ideal cache the miss rate for everything would be . So . Thus the performance gain if using an ideal cache would be -