Table of Contents
Hash table is a linear data structure which is used to create mapping between the value and the key using a hash function.
Example of a hash function -
Collision Resolution
If keys of two values yield the same output for the hash function, a collision occurs.
1. Open Hashing
If multiple elements point to the same key then we connect them to a linked list.
Example -
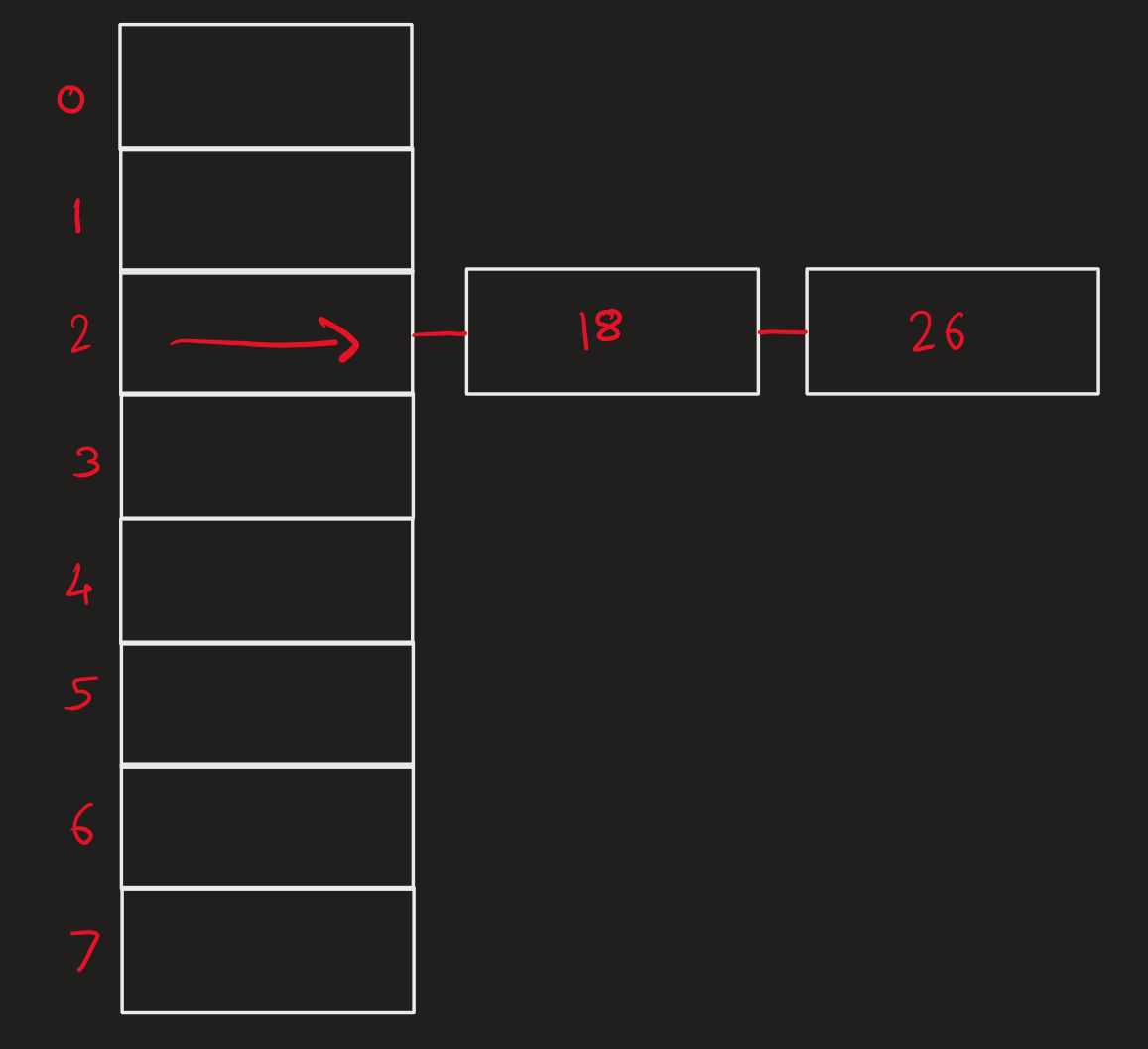
Here we have cells in our hash table and try to insert values – .
- Best case time complexity -
- Worst case time complexity -
2. Closed Hashing
All elements inserted are stored inside the hash table itself, without the use of any external data structure.
a. Linear Probing
If any index already has a value in it (collision occurs at the index), move to the next index and check if it’s free. Keep doing this until an empty index is found.
In linear probing our hash function is usually -
- Initially
- Upon collision
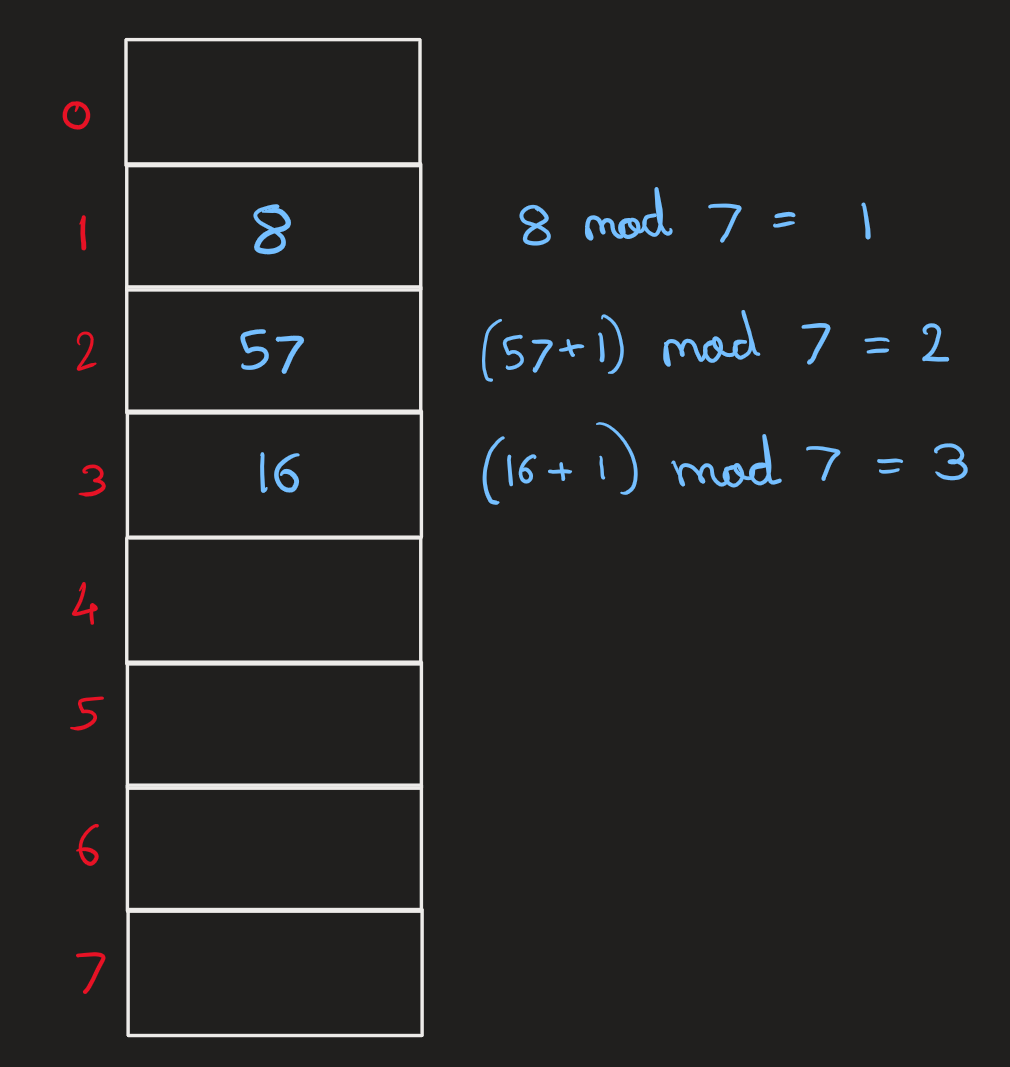
Example -
To insert -
Drawback of Linear Probing -
-
Primary Clustering - Keys that hash to different initial indices end up following the same probe sequence.
Here -
- 57 had an initial hash of 1
- 16 had an initial hash of 2 Yet both end up sharing the same probe sequence and be part of a cluster.
b. Quadratic Probing
To avoid Primary Clustering we can update the hash function to be -
Drawback of Quadratic Probing -
-
Secondary Clustering - Keys that hash to same initial indices end up following the same probe sequence.
Clusters formed using this will be smaller than primary clusters.
c. Double Hashing
In order to tackle Primary and Secondary clustering, we use two hash functions -
Summary
- Hash tables are made to decrease the time complexity required in searching for an element.
- This is done by using hash functions.
- Open hashing creates linked lists at each index of the hash table.
- Linear probing causes Primary Clustering.
- Quadratic probing causes Secondary Clustering.
- Double hashing solves both Primary and Secondary Clustering.