Deep Generative Models
Family of Deep Generative Models (DGMs) to be covered -
- Generative Adversarial Networks (GANs)
- Variational Auto Encoders (VAEs)
- Denoising Diffusion Probabilistic Models (DDPMs)
- Score Based Models
- Auto Regressive Models (AR)
- Large Language Models (LLMs)
- State Space Models (SSMs)
- Example - S4, Mamba
- RL-based Alignment for LLMs
- RLHF, PPO, DPO
Any dataset means that consists of independent realizations of i.i.d. vector valued random variables of size , each distributed according to some unknown probability distribution .
Goal - Given such a , the goal of using Generative Models is to estimate and learn to sample from it.
Principles of Generative Models -
- Assume a parametric family on denoted using where is represented using Deep Neural Networks. This is our “model”.
- Define and estimate a divergence metric to measure the distance between and .
- Solve an optimization problem over the parameters of to minimize the divergence metric.
Example
Assume some random variable with some arbitrary but known distribution (because the distribution is known, sampling is possible). Suppose there exists some function .
- would have an entirely different distribution than that of and would depend upon the function .
- Suppose is a Deep Neural Network and the density of is denoted as . We can define a divergence metric between and such that and iff .
- Solving the optimization equation , would allow us to implicitly estimate . This would allow us to sample from using because a random sample chosen from and then passed through would be very similar to a sample from .
This method is called a pushforward method as we push a probability mass into the data space using a function .
Obstacles towards implementation -
- We know random samples from these distributions, the dataset from and from , but not the distributions themselves. How to compute the divergence metric without knowing the distributions and ?
- What should the choice of the divergence metric be?
- How to choose and in turn ?
- How to solve the optimization problem of minimizing the divergence metric?
Variational Divergence Minimization
Define a divergence metrics between two distributions -
f-divergence
Given two probability distribution functions with corresponding probability density functions denoted by and , the -divergence between them is -
We write to denote that we are calculating the divergence of from , or in other words “how well does approximate “.
- Convex function - A function which has one unique minimum value (can have multiple minima).
- Strictly Convex function - A function which has only one global minima.
- Left Semi-Continuous function - A function in which the value at a point is equal to the limit when approached from the left.
- Probability density functions are always non-negative, thus their ratio will be a positive value which would satisfy the domain of .
- Range space of and would be positive scalars despite being a -dimensional random vector.
Choice of an function is what leads to an -divergence.
Properties of -divergence -
- for any choice of .
- iff .
Examples of f-divergence -
- leads to the KL (Kullback-Leilber) Divergence -
K.L Divergence is asymmetric, meaning .
- leads to the JS (Jensen-Shannon) Divergence.
- leads to the Total Variation Distance or TV Distance.
Algorithm for f-divergence minimization
We need to come up with an algorithm to optimize the -divergence without knowing what the distributions and are but instead by using the samples of and known to us (dataset and output of ).
Key Idea - Integrals involving density functions can be approximated using samples drawn from the distribution.
For an integral like the one shown below, we have i.i.d samples drawn from .
By the Law of Unconscious Statistician (LOTUS) we know that if is a random variable with a probability distribution and is some measurable function, then
By the Law of Large Numbers, we know that as the number of samples grows, the sample mean converges to the true expected value of a function .
So one way to solve an integral like the f-Divergence is by using the above two mentioned laws and equating it to the expected value of function . It would be a mathematically valid representation but is not directly computable from the data since the true data distribution is unknown.
Conjugate of a convex function
The conjugate of a convex function (Fenchel Conjugate) is written as -
- Here belongs to the domain of , but isn’t from the range of .
- is some arbitrary vector in that is used to probe .
- is used to make a linear function where defines the slope of the linear function.
- The conjugate checks by how much does this linear function outperforms .
At every point , one constructs multiple lower bounds on that particular and chooses the tightest of those lower bounds (supremum/max) as value of the conjugate.
Properties of a conjugate of a convex function -
- is also a convex function.
Using these properties of a conjugate of a convex function, we can write as -
Substituting this in the f-Divergence Integral we get -
To represent the -divergence in terms of expectation, we need to somehow take the supremum out of the integral. Since the Fenchel conjugate expresses as a pointwise supremum, and since depends on , the optimizer of the inner problem is generally a function of . Due to this, we can’t just take the supremum out of the integral as it is.
Here the solution of the inner optimization problem is some function of . So, if we express we can take the supremum out and rewrite the equation as -
where is the space of functions containing solutions for the inner optimization problem.
For the solution of the inner optimization problem is maximal. Because we are allowed to pick any arbitrary as this point, this optimal can be achieved. But upon restricting by considering a function that belongs to a class of function , if lies outside the range of then need not be maximal anymore. Thus in such a case -
For the sake of understanding, we can replace in the above equation with .
Realization of VDM (Variational Divergence Minimization)
We need a that minimizes the -divergence . is not optimizable due to being unknown. At the true optimum the lower bound on becomes a tight bound, thus making the optimization of and the optimization of the lower bound equivalent.
The final objective here requires two optimizations -
- Generator Network - The outer minimization w.r.t parameters of .
- Critic/Discriminator Network - The inner maximization w.r.t a class of functions .
With this the objective becomes -
Neural networks enter the framework when we need to perform the saddle-point optimization of the variational lower bound of the -divergence, since both the generator distribution and the variational function are infinite-dimensional objects.
- The model distribution must be learnt to reduce the value of the -divergence metric. Neural networks provide a flexible and differentiable parameterization for learning such complex data-generating distributions using the samples.
- The function class , being infinite dimensional, is difficult to characterize explicitly. As neural networks are universal function approximators, we represent using neural networks where are the parameters of the neural network.
Implementing VDM for Generative Modelling
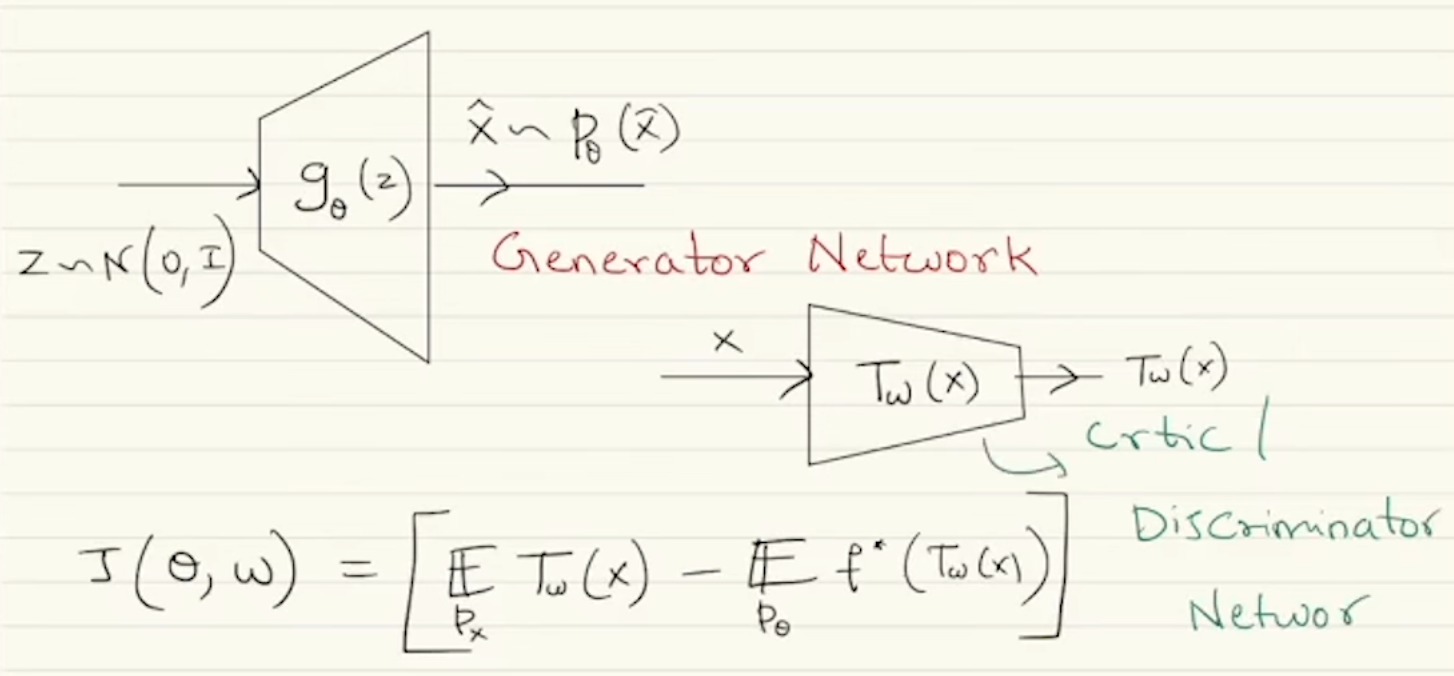
Now we have two neural networks, one representing the sampler (Generator Network) and the other representing the function class (Critic Network).
Such problems are called a saddle-point optimization problems as we are looking for saddle points here or an adversarial optimization problem because whatever one network is trying to do is the opposite of what the other network is trying to do.
Usually we avoid saddle-points because they are neither a global minima nor a global maxima, but this is one of the rare instances where we seek a saddle point.
By construction is dependent upon the particular choice of . can be rewritten as to guarantee that the critic’s output lies in the domain of while keeping the network architecture independent of our choice of the -divergence. Here -
- is a function common across all -divergence
- is an -divergence specific activation function (need not always be the sigmoid function)
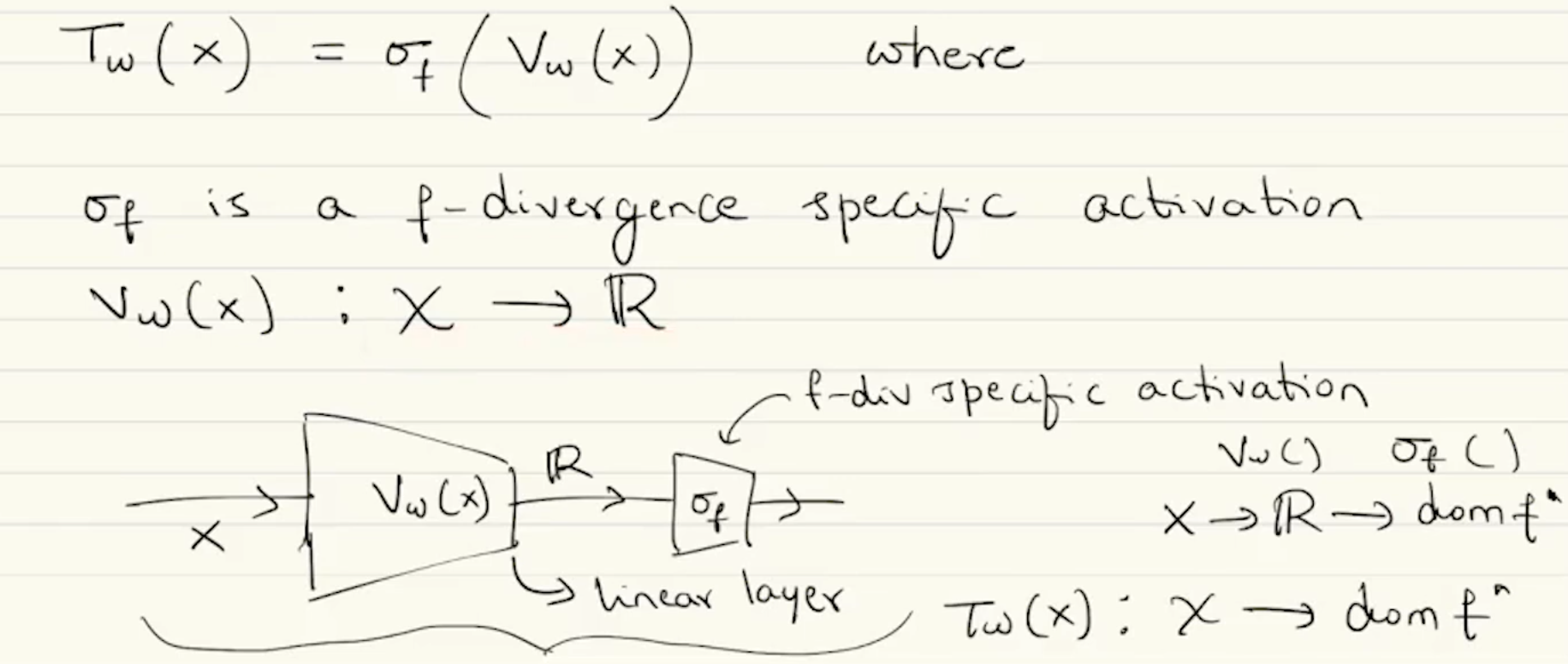
So we can rewrite our loss function as -
Generative Adversarial Networks
For GANs the -divergence that is chosen is as follows -
The log-sigmoid as ensures that the output of the critic always lies in . Using the above information, we can write a GAN specific loss function using the equation of the loss function we got earlier.
Observations to note -
- Due to the rearrangement of terms again satisfying the lower-bound equation, we can see that .
- It can also be seen that this objective function strangely resembles the cross-entropy loss.
- The discriminator would try to maximize this “cross-entropy” by maximizing the objective function. Since the cross-entropy is large when real and fake samples are easily distinguishable, maximizing it encourages the discriminator to separate samples from and as effectively as possible. Thus it is called the “discriminator.”
- The generator would try to minimize this “cross-entropy” by only minimizing the second term of the objective function. In general this second term penalizes incorrect predictions made with a high probability. In this case it would be penalizing the fake samples the discriminator confidently distinguishes as fake. By minimizing it, the generator encourages the discriminator to assign higher probabilities to generated samples, which implicitly pushes the generator distribution towards the data distribution .
- The above two observations are solidifying more in Formulation of classifier guided sampler.
- The discriminator is trying to assign a low probability to the generated samples while the generator pushes the discriminator to assign them a high probability. This causes the adversarial nature of the networks.
The architecture ends up looking like the image below. doesn’t need to be included in the discriminator network as it is not a part of the networks but the error function.
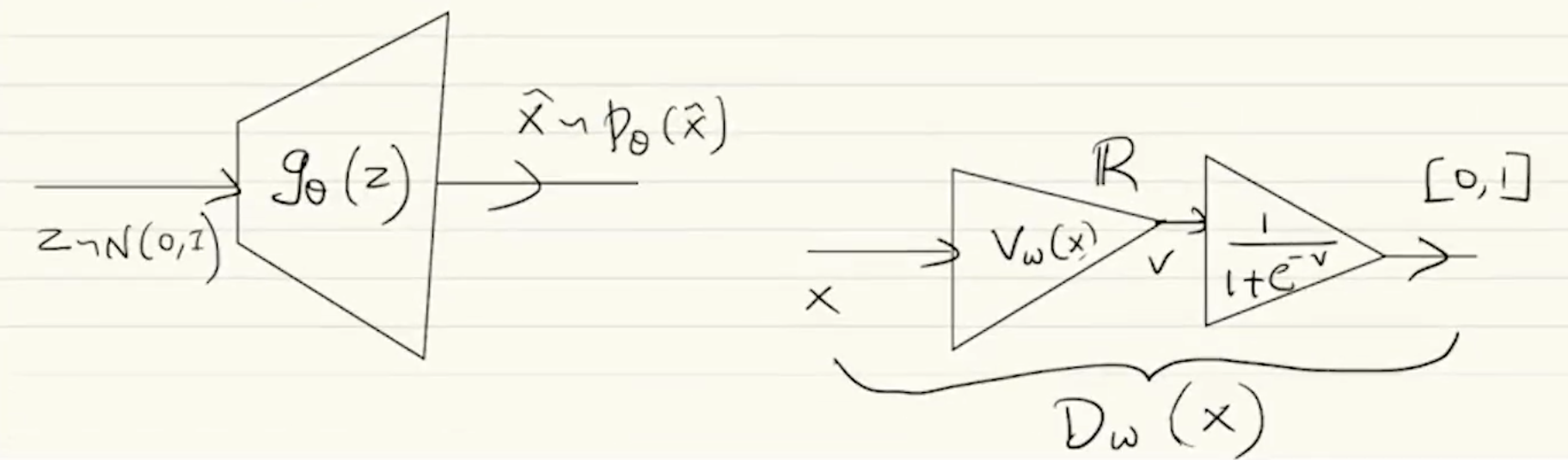
Implementation of GAN in practice
Pre-requisites -
- Input .
- Let (need not be contiguous, is usually random) be a mini-batch taken from the dataset.
- Let be a batch of random noise vectors taken from the arbitrary distribution we chose, typically .
As we are using these batches during Mini-Batch gradient descent, these batches are resampled each time before an update.
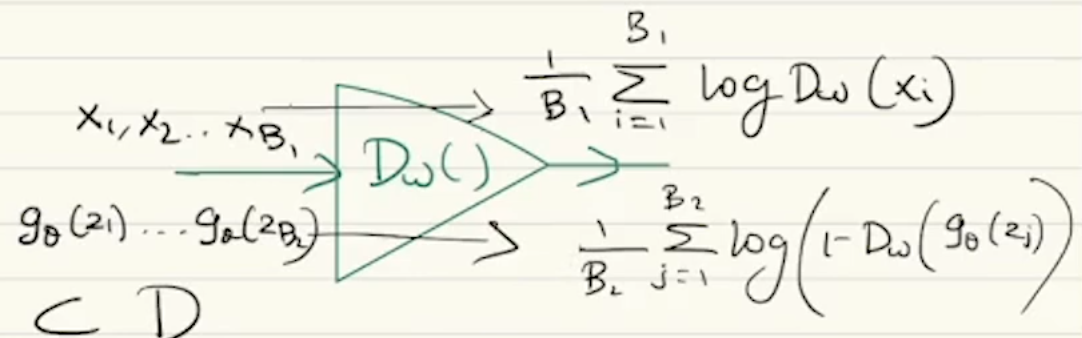
To train the Discriminator
Optimizing for -
Steps -
- Resample and .
- Pass through the discriminator to get . Then using these calculate the first term of the loss function -
- Keeping constant, pass the random noise vectors through the generator to generate fake samples . Pass this through the discriminator to get . Using these calculate the second term of the loss function -
- Calculate the gradient and backpropagate the gradients back through the discriminator network.
- Update using gradient “ascent”.
To Train the Generator
Optimizing for -
Steps -
- Resample .
- Keeping constant, pass the random noise vectors through the generator to generate fake samples . Pass this through the discriminator to get . Using these calculate the term of the loss function -
- Minimizing the above term is mathematical valid but in practice can lead to vanishing gradients. So instead we can maximize the following term -
- Calculate the gradient and backpropagate the gradients back through the discriminator network and then through the generator network. The discriminators parameters are not updated as is set to constant.
- Update using gradient descent.
We have to solve these optimization problems alternatively. First update the generator parameters while keeping the discriminator parameters are constant, then update the discriminator parameters while keeping the generator parameters are constant.
Interpretation of GANs as Classifier guided Generative Samplers
In GANs the discriminator network acts as a binary classifier which is able to predict whether a given sample belongs to or .
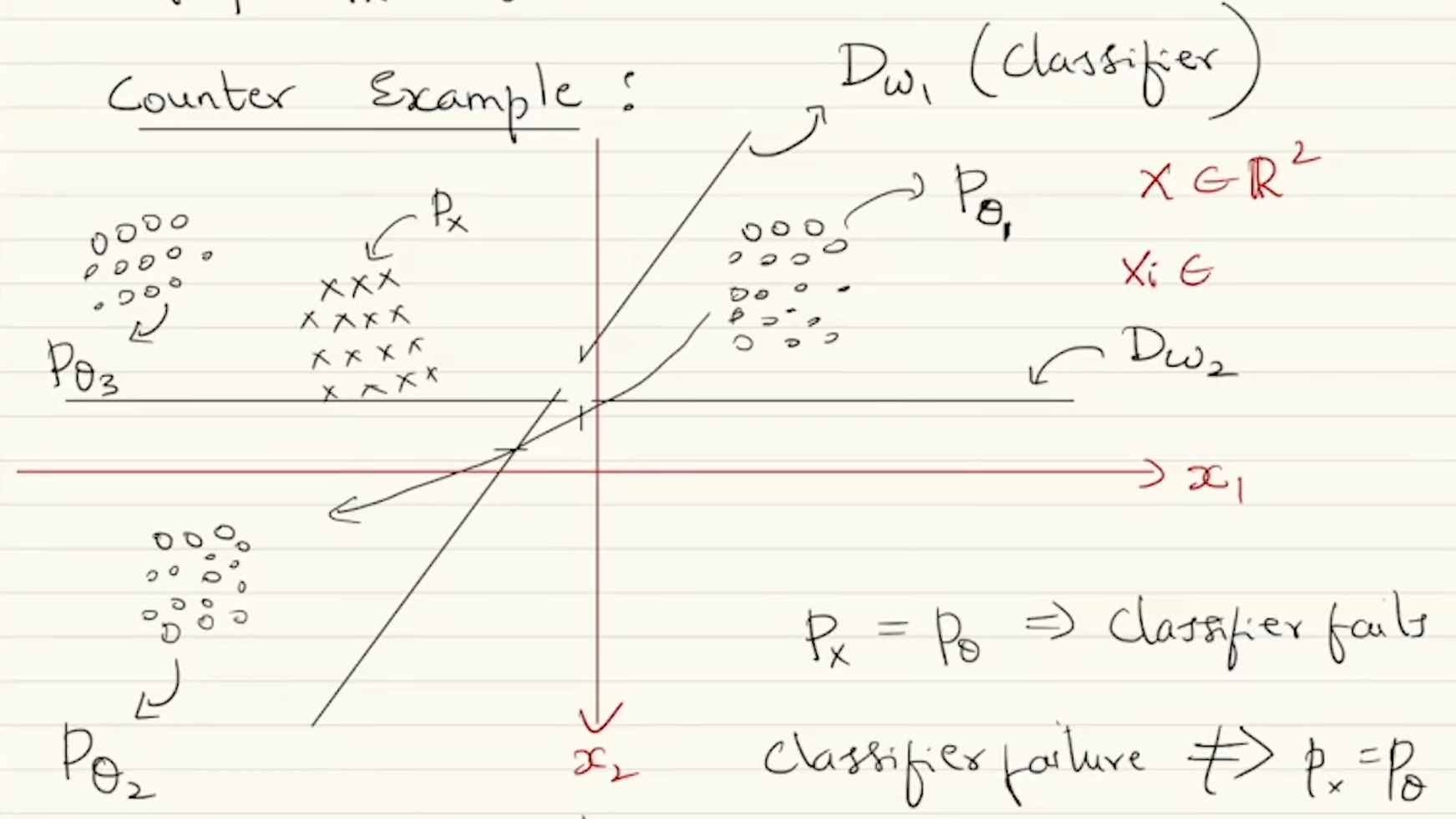
*Can this classifier be used to bring and closer?
- Yes! If and were sufficiently close to each other, even an optimal discriminator would fail to distinguish the samples between them. So we can tweak till the classifier fails to distinguish between samples of and .
- However, the failure of some weak or arbitrary classifier doesn’t imply that and are close to each other. So instead of just tweaking , we also need to change the binary classifier . If all such different variations of the classifiers fail to distinguish the samples then we can confidently say that and are close to each other.
Mode Collapse Problem -
- During the updation of the generator and the classifier, it can happen that and the classifier keep alternating between two values and get stuck in an infinite loop. This is called the mode collapse problem.
Formulation of classifier guided sampler
Creating the classifier -
- Let represent the probability of the sample coming from .
- We’d need to maximize the log-likelihood of coming from when (probability of real samples being marked as real) and also maximize the log-likelihood of coming from when (probability of fake samples being marked as fake). So the combined objective of the classifier becomes maximizing the sum of these two values.
Similarly for the generator -
- The objective for the generator is that the classifier has to “fail” in distinguishing samples from and . So the goal here is to minimize the discriminator’s confidence that fake samples coming from are fake.
Thus the overall objective becomes -
Deep Convolution GAN (DC GANs)
Typically in a GAN, the dimension of the noise variable is much less than the dimension of the data. In DC GANs we can use the upconvolutional or transpose convolutional layers to convert this noise data to a higher dimensional data.
Additionally:
- DCGANs remove fully connected layers and use fully convolutional architectures in both the Generator and Discriminator.
- The Generator upsamples noise using transpose convolutions, while the Discriminator downsamples images using strided convolutions (instead of pooling).
- Batch Normalization is used in most layers to stabilize training and reduce mode collapse.
- Activation choices are fixed: ReLU (Generator), LeakyReLU (Discriminator), Tanh at Generator output, Sigmoid at Discriminator output.
- Careful weight initialization (often normal with small variance) is important for stable training.
- These architectural constraints help DCGANs learn spatial hierarchies in images and improve training stability compared to vanilla GANs.
Conditional GAN (cGAN)
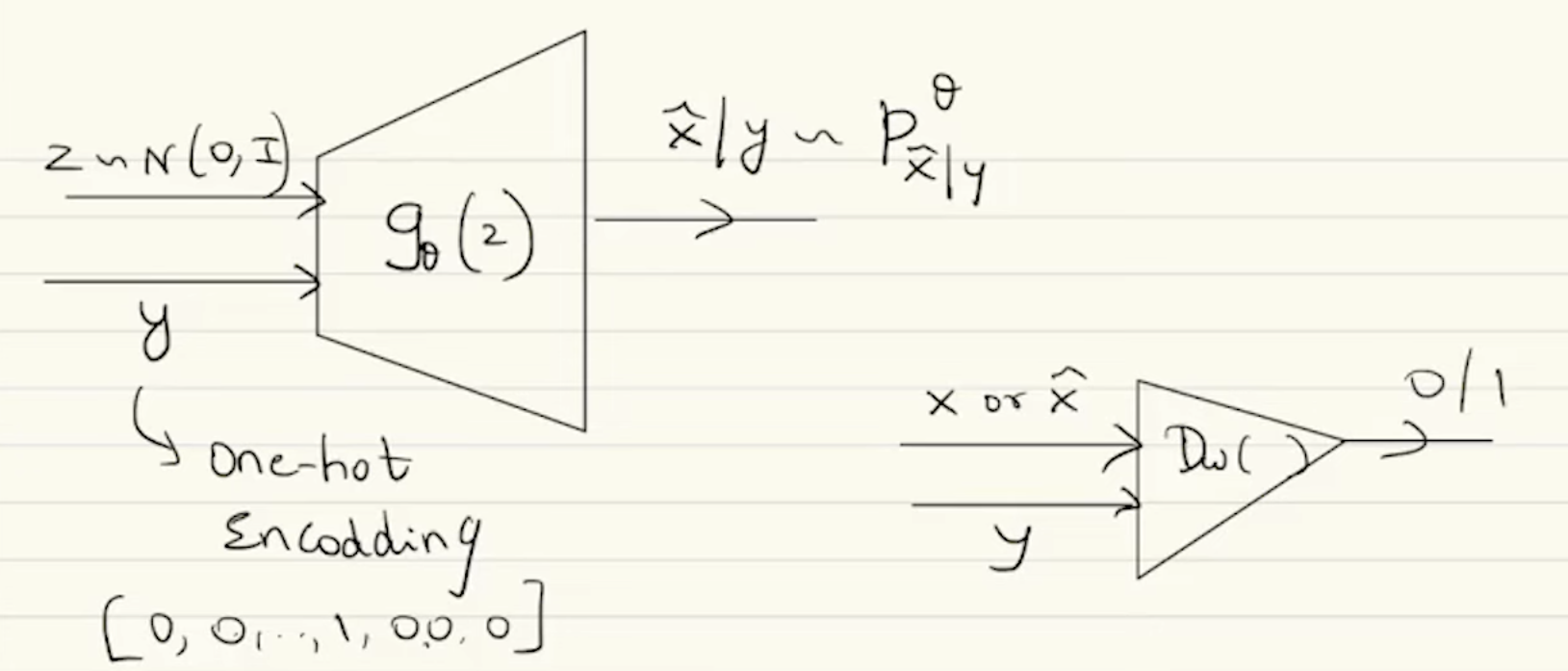
To make conditional GANs that sample from a conditional distribution, we pass the conditional variable through both the generator and the discriminator.
- Instead of just the noise we pass so the generator learns .
- Instead of just seeing , the discriminator sees . It now answers “Is a real sample consistent with condition “.
The objective function changes to -
Inference with GANs/VDM
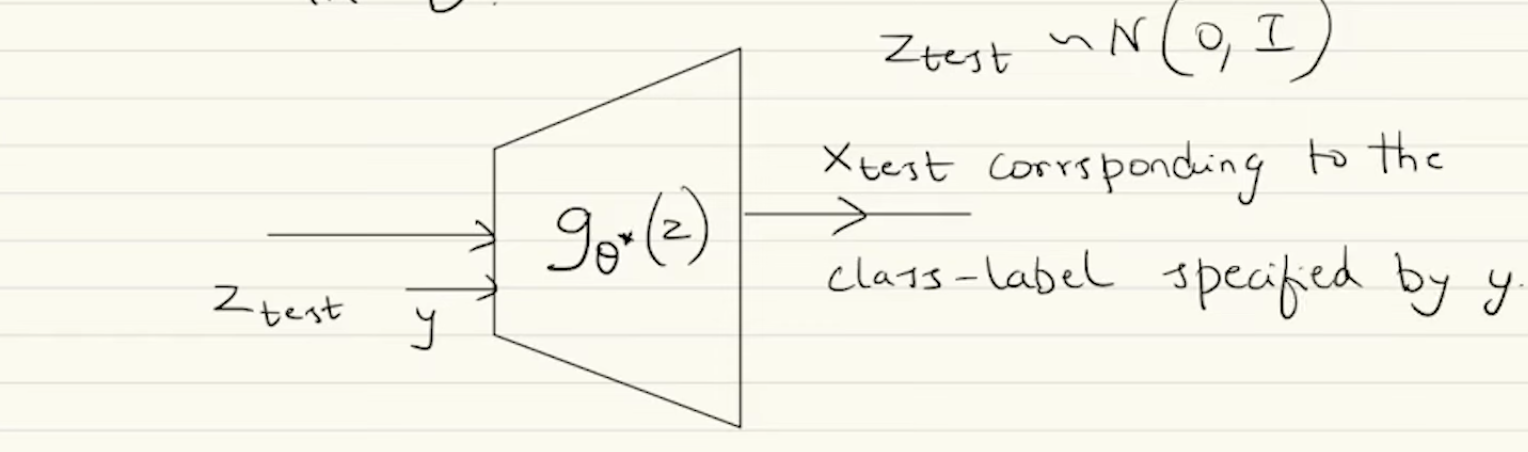
Suppose is the optimal generator network achieved via training. For any test input and class label , the output would be a corresponding to the class-label specified by .
Improvisations and Applications of GANs
Wasserstein’s GANs (WGANs)
What makes GAN training unstable?
Manifold Hypothesis -
- Images in the real world lie in a lower dimension manifold of the ambient space .
- Consider all images such that a pixel is 1 if a coin toss results in a heads, else 0. The probability of an image generated in such a manner resembling an English Alphabet is very low. So we can say that the images depicting an English Alphabet lie in a low dimensional manifold on the ambient space .
- Similarly an image of any natural object lies in a lower dimension manifold of the image’s dimension .
The real distribution and the generated distribution are both distributions over . Since the real data and the generated data would lie over a lower dimensional manifold of , the supports (set on which the corresponding density function has a non-zero value) of and would misalign with a very high probability.
When the supports of and misalign, it can be shown that a perfect discriminator would always exist. In such a case the gradient of the discriminator becomes 0, due to which the discriminator parameters and the generator parameters can’t be updated any further (gradients flow through the discriminator into the generator). Thus GAN training saturates.
Remedies for GAN training saturation -
- Train the generator and the discriminator at different training ratios, usually training the generator more.
- Instead of using the -divergence metric which becomes independent of the generator parameters when GAN training saturates, use a “softer” metric which does not saturate when the manifolds of the supports of and misalign.
Wasserstein’s Metric (Optimal Transport)
Given two distributions and ,
Here corresponds to a “transport plan” that requires the least amount of “work done” in redistributing to be similar to .
Derivation (Not Rigorous) -
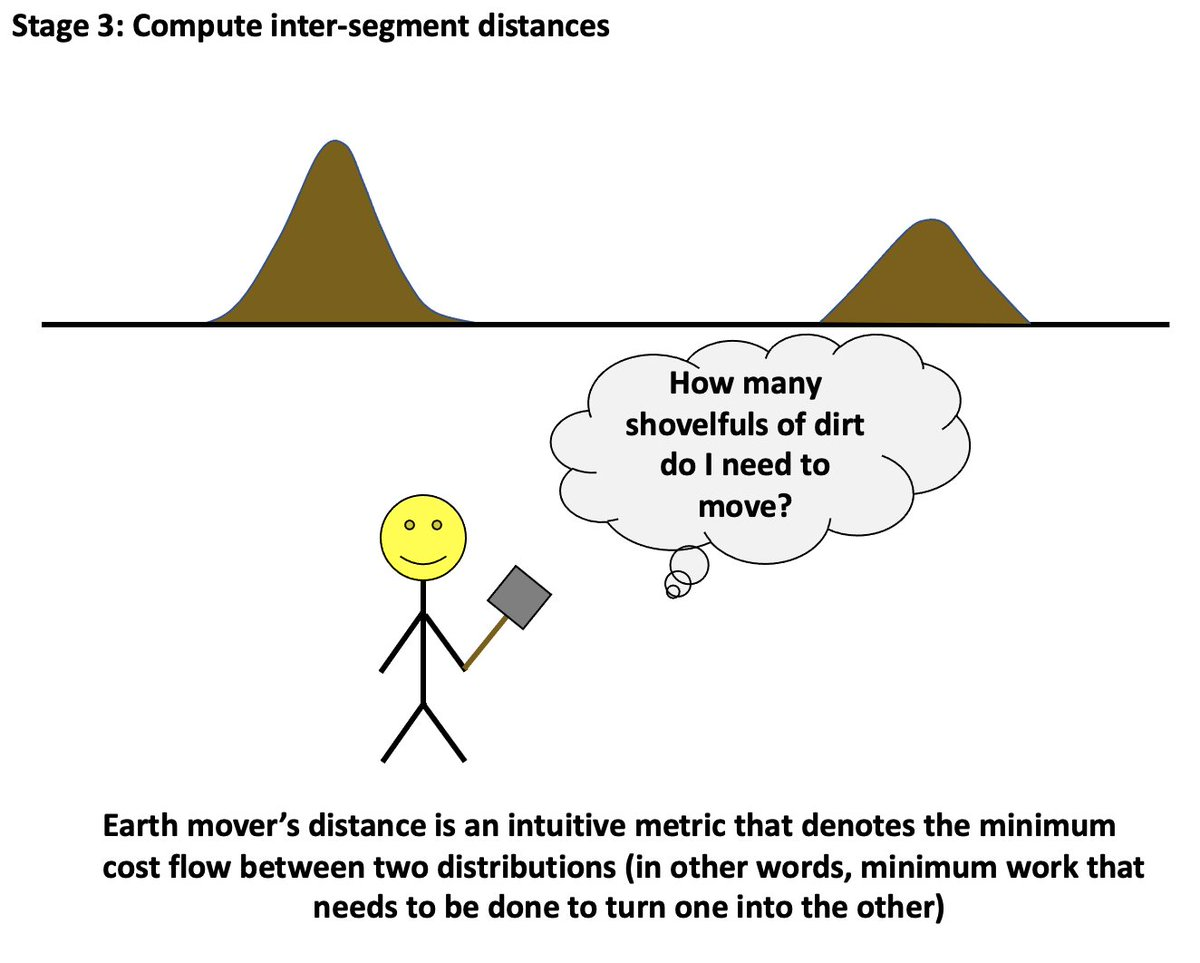
Imagine piles of dirt here to be and to be a pile of dirt shaped like a bell curve. The minimum transport plan just tells you the best plan to shovel dirt in between the two piles such that the final pile resembles .
But how does shoveling dirt relates to redistributing distributions? Every joint distribution between the two distributions and can be written as a table whose each row and column sum to 1.
| 0.3 | 0.2 | 0.3 | ||
| 0.9 | 0.1 | 0 |
This joint distribution between the two marginals and is a transport plan which tells how one of the marginals can be transformed into the other. To quantify the “effort” required in a transport plan, we can use the concept of work done ( ) from Physics. In our context -
The average work done required in a transport plan is -
Let be the family of all joint distributions/transport plans between the marginals and We are interested in finding the transport plan which requires the least amount of work done -
This is the Wasserstein’s Metric.
How to minimize Wasserstein’s Metric
The Wasserstein’s Metric is a minimization problem. Every minimization problem has a dual maximization problem. One such result of min-max duality is the Kantrovic-Rubenstein’s Duality states -
Any function being 1-Lipschitz means that the function cannot change faster than the distance (the derivative is always less than or equal to 1) -
The in this case is a neural network and can be made 1-Lipschitz by normalizing the weights of such that after each gradient step.
has to be such that the Wasserstein’s distance is to be minimized. The Kantrovic-Rubenstein’s Duality enables us to express the Wasserstein’s distance in terms of expectations of and .
The above objective is very similar to GANs. That’s why this method of minimizing the Wasserstein’s metric is called the WGAN. Training a WGAN is more stable than training a Naive-GAN as the gradients will not saturate if the supports of the probability distributions misalign.
Bi-Directional GAN (Bi-GAN)
Inversion of GANs
We train a GAN specifically to allow us to sample from the dataset distribution by picking a random sample from an arbitrary distribution and passing it through the generator . But how can we get back if we know ?
Inversion is useful for -
- Feature Extraction - Knowing any sample and the inversion of our GAN can allow us to obtain GAN-inverted vectors and use them as features for the data.
- Data Manipulation/Editing - Suppose a GAN is trained on images. If we wish to edit an image using the GAN itself, we need to know the corresponding latent vector (input vector ) for that image and edit this vector in such a way that the image corresponding to this edited input is our desired output image.
Bi-Directional GAN
In Bi-GAN, in addition to the generator and the discriminator networks there’s also the Encoder/Inverter network denoted as .
Here the discriminator won’t just take and as the inputs to distinguish between but take a pair of values and as the input and attempt to distinguish the joint pairs. If the discriminator fails to do so, we can say that .
The objective function is -
Here and are trained simultaneously using the discriminator. Once train acts as the generator and is used for inversion. It can be shown that,
Latent Regression
where is a hyperparameter. Here the discriminator remains the same as the naive regressor. It has been found that
Domain Adversarial Networks
Suppose we have a source dataset and target dataset such that both belong to a different distribution.
When the probability distribution of your training and testing dataset differ, we call this as domain shift.
Any classifier/regressor trained solely on would fail to predict for the target items in .
Example
Imagine you're training a model to identify images of dogs. The training dataset for your model has sketches, paintings, and cartoon representations of dogs while you test dataset has actual photos of dogs. In such a case the distributions for the training and testing dataset differ. The method to solving domain shift is called as **Unsupervised Domain Adaptation**.In the above example -
- The broader class of “animal representations” is a semantic class.
- The sketches, paintings, cartoons, and photos are called as domains.
The network can be trained either on all four domains or one of the domains can be unknown. In the case where a domain is left out, our hope is that all domains share the same underlying semantic structure just with different marginal distributions. This is called as the shared support assumption. Under this assumption, an optimal encoder trained on the rest three domains should be able to extract meaningful features from the unseen domain. This setting is called domain generalization.
So our objective with such a setup would be that our model is able to learn the features/classifier in such a manner that it’s able to perform well on both and .
We can use Domain Adversarial Networks here to train a classifier that is domain agnostic (able to classify independent on which domain element belong to).
In Domain Adversarial Networks we have -
- An Encoder to extract features from inputs regardless of which domain the inputs belong to (both and ).
- A Discriminator to distinguish between elements of and elements of (Features of both source and target data).
- A Classifier/Regressor which uses the features of the source inputs to make a prediction regarding their target. This works as a metric for the usefulness of the features.
A DANN cannot generate samples, it’s only job is to align the features of the different distributions.
The Discriminator makes the Encoder better at constructing features from the inputs (both source and target) in such a way that the features appear domain agnostic. But just having domain agnostic features isn’t all, they need to be useful for predicting the target class. For this we include a Classifier/Regressor as well in the network so that the features learnt are both domain agnostic and useful.
The encoder network has gradients flowing from both the discriminator as well as the classifier.
- would ensure that = .
- would ensure that the features are meaningful.
Evaluation of a GAN
Suppose we have some true and generated samples and we wish to evaluate whether the GAN is successful in generating samples from . There are various methods for it, but we’d be look at an adversarial method of evaluation called Fréchet Inception Distance. FID uses Wasserstein’s Metric along with Inception Network trained on Imagenet to do this evaluation.
Let -
- Take a pretrained Inception Network trained on the Imagenet dataset. Let this be denoted as .
- Pass and through and extract the features for and from some layer of .
- Compute the mean and covariance for and .
- Assume that the features of the true and generated data come from a Gaussian distribution of corresponding mean and variance.
- Calculate the Wasserstein’s Metric between and . This is the FID, our evaluation metric of the GAN.
and would never be equal because of the heavy amount of approximations made for VDM. The GAN trained is better if the FID is lower. Lower FID means lower distance between and .